
I Built a Self-Hosted Music Discovery Pipeline That Automatically Syncs Radio Tracks to Spotify Using N8N
A step-by-step guide to building an automated workflow that extracts music data from radio APIs and seamlessly integrates with Spotify's ecosystem.

What This Project Is About
This N8N workflow automatically synchronizes tracks from Polish radio station "Radio Kampus" to a Spotify playlist. The system retrieves currently played songs from the radio's website API, searches for them on Spotify, and adds found tracks to a dedicated playlist. Every day at midnight, the playlist is cleared and the process starts fresh, ensuring you always have the latest music from the station.
You can check out the live playlist here: LINK
Why I Built This
I'm a regular listener of "Radio Kampus," Warsaw University's radio station, because they play diverse music genres instead of just mainstream pop like other popular stations. They have a dedicated webpage showing their current playlist, but since I primarily use Spotify for music, I found myself manually searching for and adding interesting tracks I heard on the radio.
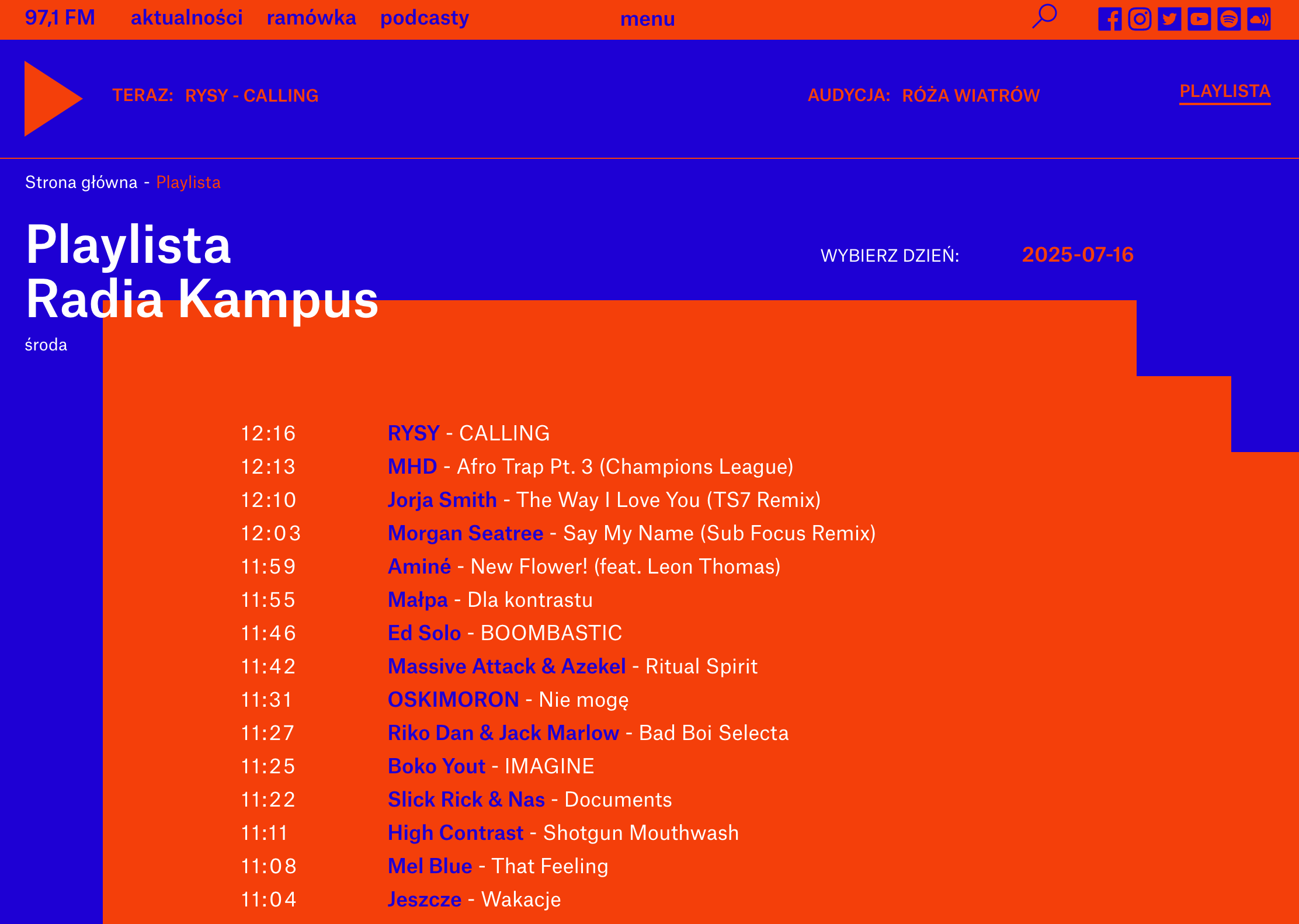
This manual process became tedious, so I decided to automate it. The workflow solves two main problems:
Radio talk vs. music: Sometimes I want to hear just the music without radio commentary
Easy music discovery: I wanted a seamless way to add Radio Kampus tracks to my Spotify library
The automation creates a bridge between radio discovery and my personal music streaming experience.
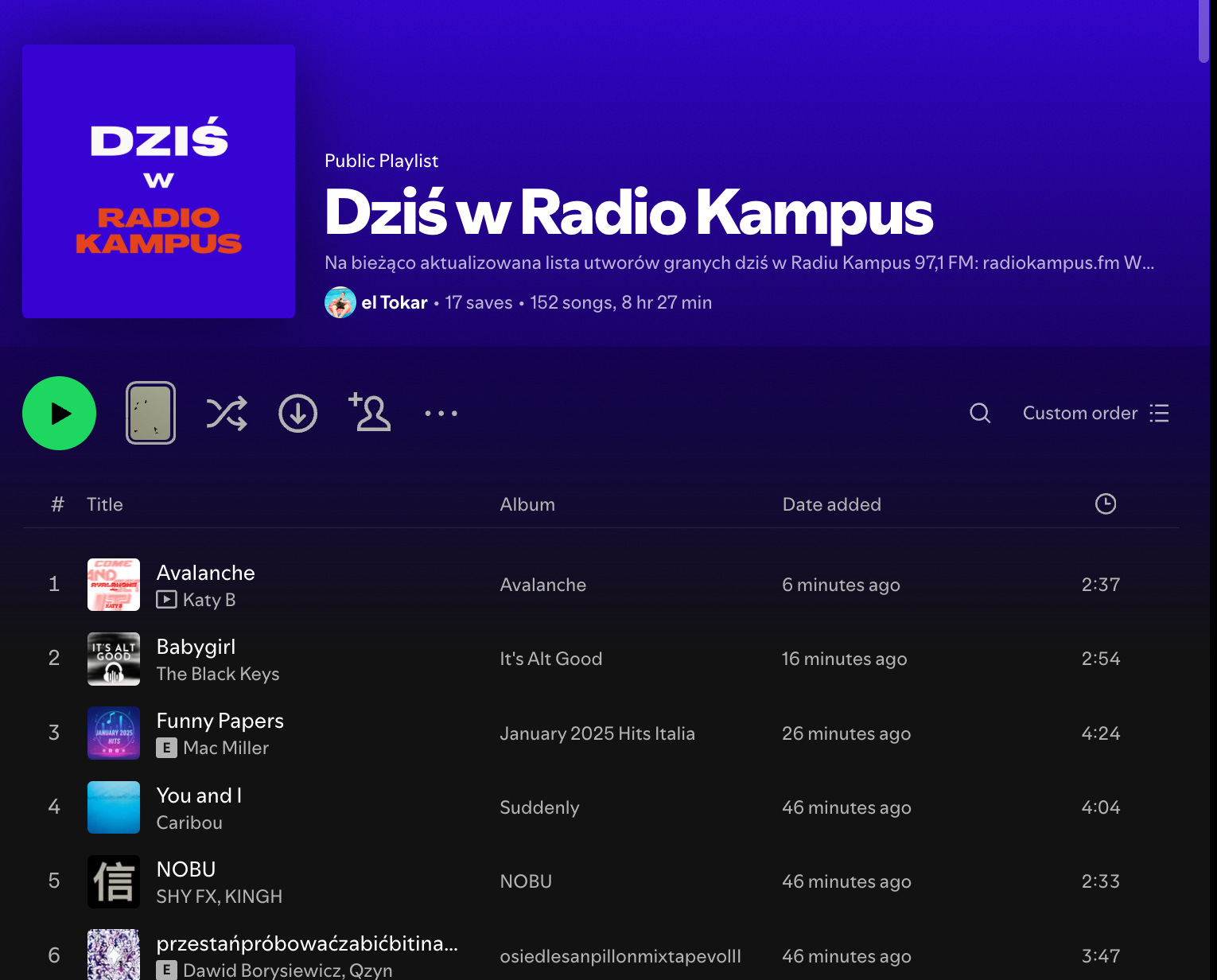
How the Workflow Works
Data Collection from API
Instead of using web scraping libraries like BeautifulSoup as I might have done in the past, I discovered that the Radio Kampus playlist page uses a simple GET request that returns song data in JSON format. This approach is more reliable and efficient than parsing HTML.
Using Chrome Developer Tools, I opened the Network tab and refreshed the playlist page to identify the API endpoint. The request returns a complete list of tracks with metadata, making data extraction straightforward.
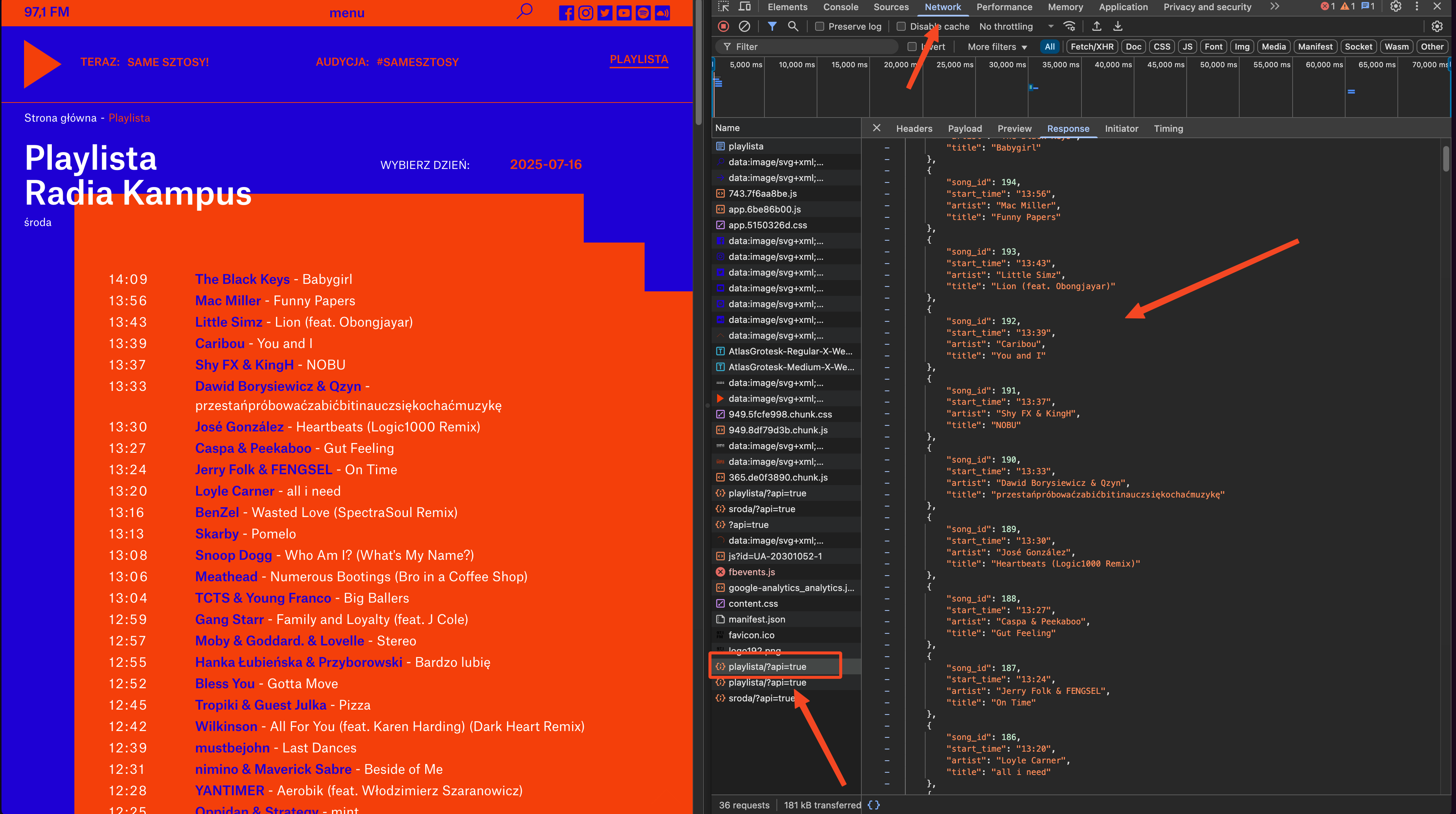
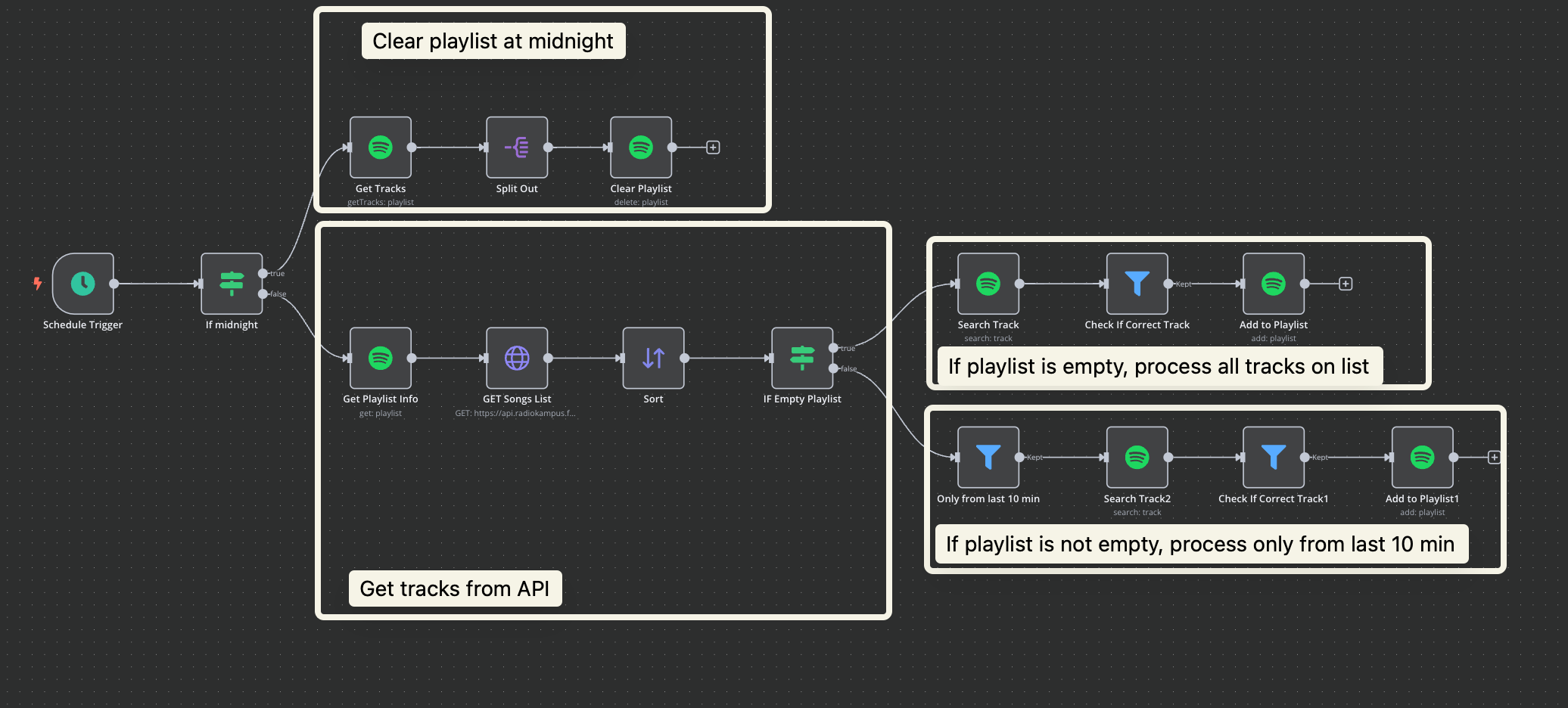
N8N Workflow Logic
I chose N8N because it provides an excellent platform for rapid prototyping with built-in integrations for services like Spotify. It's free to use and runs perfectly on my homelab setup.
💡 Note: While this workflow focuses on music automation, the same principles apply to any API-to-API data synchronization project. N8N's visual interface makes it perfect for rapid prototyping of data pipelines.
The workflow operates as follows:
Executes every 10 minutes via scheduled trigger
At midnight, clears the entire playlist to start fresh each day
Retrieves data from Radio Kampus API to get current track listings
Checks if the playlist is empty:
If empty: searches for all tracks from the radio's current playlist
If not empty: searches only for tracks added in the last 10 minutes
Adds found tracks to the Spotify playlist after verification
⚠️ Warning: Always respect API rate limits and terms of service when building automated workflows. Sites have usage restrictions that should be carefully monitored.
The search verification logic ensures accuracy by checking if the Spotify search result contains the original track name from the radio. For example, if Radio Kampus plays "Ocean Floor" and Spotify returns "Ocean Floor feat. XYZ," the track is accepted because it contains the original title. This prevents false matches where Spotify might return completely unrelated songs.
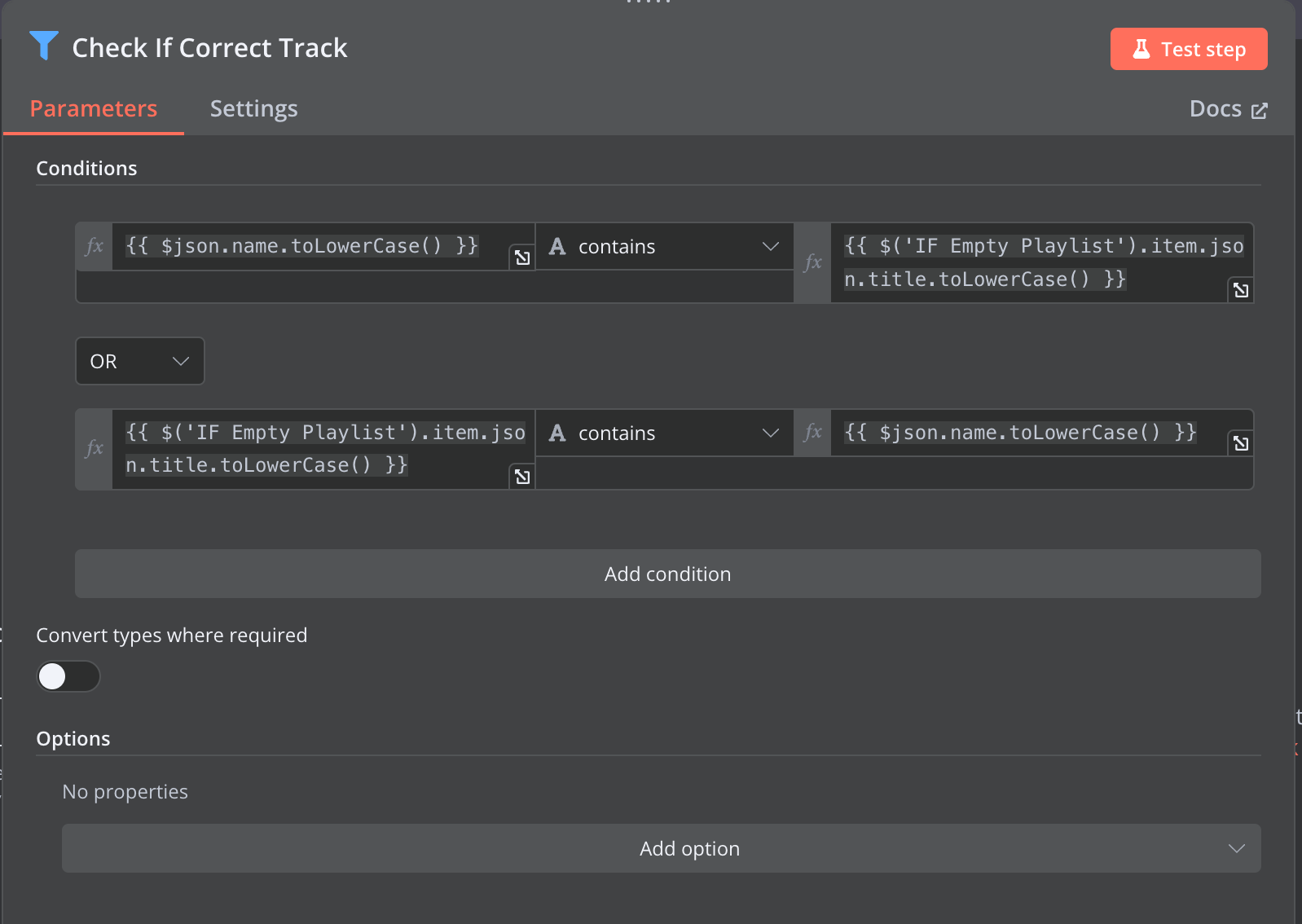
Problems and Limitations
While the workflow has been running successfully for months, there are several areas for improvement:
Search Algorithm Limitations:
The matching logic relies on simple string containment, which may fail with different artist name spellings
Remix versions (e.g., "Song Title (Radio Edit)") might not match the original "Song Title"
Polish characters in artist names can cause search failures
No fuzzy matching for slight variations in track titles
API Dependency Issues:
If Radio Kampus changes their API format, the workflow will break without immediate notification
Currently, there's no monitoring system to alert me when data parsing fails
The workflow assumes the API structure remains consistent
Spotify Integration Challenges:
Spotify's search API sometimes returns popular songs instead of exact matches
No handling for region-restricted tracks that might not be available in my location
Limited ability to distinguish between different versions of the same song
🔧 Pro Tip: Store your API credentials securely in N8N's credential system rather than hardcoding them in the workflow. This makes maintenance and sharing much safer.
Effectiveness and Performance
The workflow has been running reliably for several months without any major failures. Songs are automatically added to the playlist daily, and the system hasn't experienced any crashes or extended downtime. While I haven't conducted a detailed analysis of false positives and false negatives in track matching, the general accuracy appears high based on manual spot-checks of the resulting playlist.
Setup Requirements
To implement this workflow, you'll need:
Prerequisites:
N8N installed and running (self-hosted or cloud)
Spotify Developer account with API credentials
Basic understanding of API authentication
Configuration Steps:
Set up Spotify API credentials in N8N
Configure the target playlist ID in the workflow
Adjust the execution schedule (default: every 10 minutes)
Test the Radio Kampus API endpoint accessibility
Download Files
The complete workflow is available for download below. Before using it, you'll need to customize:
Spotify authentication credentials for your account
Target playlist ID where songs should be added
Execution frequency (currently set to 10 minutes)
Source adaptation if you want to use a different radio station or music source
N8N workflow file ready for import:
Radio_Kampus_Today.json or clone from Github.
You can also like
How We Cut Our Snowflake Pipeline Complexity Using Dynamic Tables
CSVDIFF: How We Cut Database CSV Comparison Time from Minutes to Seconds
Cheers,
Patrick
P.S. If you implement this workflow, I'd love to hear about your music discoveries or any improvements you make to the matching algorithm! Also, if you spot something that could be improved in my workflow or have ideas for enhancements, please share them in the comments.
Thanks for this man! I added some extra logic so that the workflow ignores any duplicate tracks by comparing the external track URL's within like 10 items (getting the tracks from the spotify playlist and comparing them to check if correct track), so any recent duplicates don't get added. Did this by comparing datasets.
Cheers for the work :D