
Autoencoders vs Linear Methods for Lossy Image Compression
Comparing PCA, DCT (used in JPEG), and convolutional autoencoders for lossy image compression on MNIST dataset with quantitative SSIM evaluation

TL;DR: Compared PCA, DCT, and convolutional autoencoders for lossy compression on MNIST at 33% compression ratio. Autoencoders achieved the best reconstruction quality (SSIM 0.97) compared to PCA (0.71) and DCT (0.61), though they require dataset-specific training unlike DCT.
Summary
Experiments were conducted on the MNIST dataset, comparing principal component analysis (PCA), discrete cosine transform (DCT) (used in JPEG) in three variants, and convolutional autoencoders as lossy compression methods. Compression level of 33% was evaluated using the SSIM measure and visual analysis. Autoencoders achieved the best results (average SSIM 0.97), clearly outperforming PCA (0.71) and DCT (0.61), providing the highest reconstruction quality. Limitations of PCA and autoencoders result from the need for prior training on a specific dataset. DCT does not require training but has lower decompression quality. The obtained results may be specific to the simple MNIST dataset and require verification on more complex data.
Image Compression Background
Data compression reduces the original number of bits used to represent data while attempting to preserve as much detail as possible through various methods.
Lossy Compression
In lossy compression, we lose some detail from the original image. However, this allows us to achieve higher compression ratios. In these methods, typically the higher compression ratio we set, the more detail we lose. The loss of detail is not always visible and depends heavily on screen quality and viewing distance.
Lossless Compression
Lossless compression preserves all original image information but achieves lower compression ratios compared to lossy methods. The reconstructed image is identical to the original at the pixel level.

Selected Methods
Principal Component Analysis (PCA)
Principal Component Analysis is a dimensionality reduction method used in data analysis and image compression. The main goal of PCA is to find a new coordinate system where input data is transformed into new variables.
The transformed data consists of linear combinations of original variables, ordered by decreasing variance. The first principal component represents the largest portion of data variance, and each subsequent component is orthogonal to previous ones while describing the maximum remaining variance.
The dimensionality reduction process involves selecting a limited number of principal components corresponding to the highest variance. This typically means discarding vectors associated with low variance, resulting in some information loss. Reducing the number of dimensions effectively decreases data size, enabling compression.
Discrete Cosine Transform (DCT)
The Discrete Cosine Transform is one of the fundamental tools used in image compression and processing. DCT is employed in many data compression tools for both images (JPEG format) and video (MPEG, JVT).
DCT represents an image as a sum of two-dimensional cosine functions with different amplitudes and frequencies. One key property of DCT is that in typical images, most essential information is contained in a few DCT coefficients corresponding to low frequencies. This property makes it suitable for lossy image compression.
DCT is used in the JPEG compression algorithm. The input image is divided into 8×8 pixel blocks, and two-dimensional DCT is computed for each block. The coefficients then undergo additional processes that optimize compression efficiency, including masking DCT coefficients using binary masks.
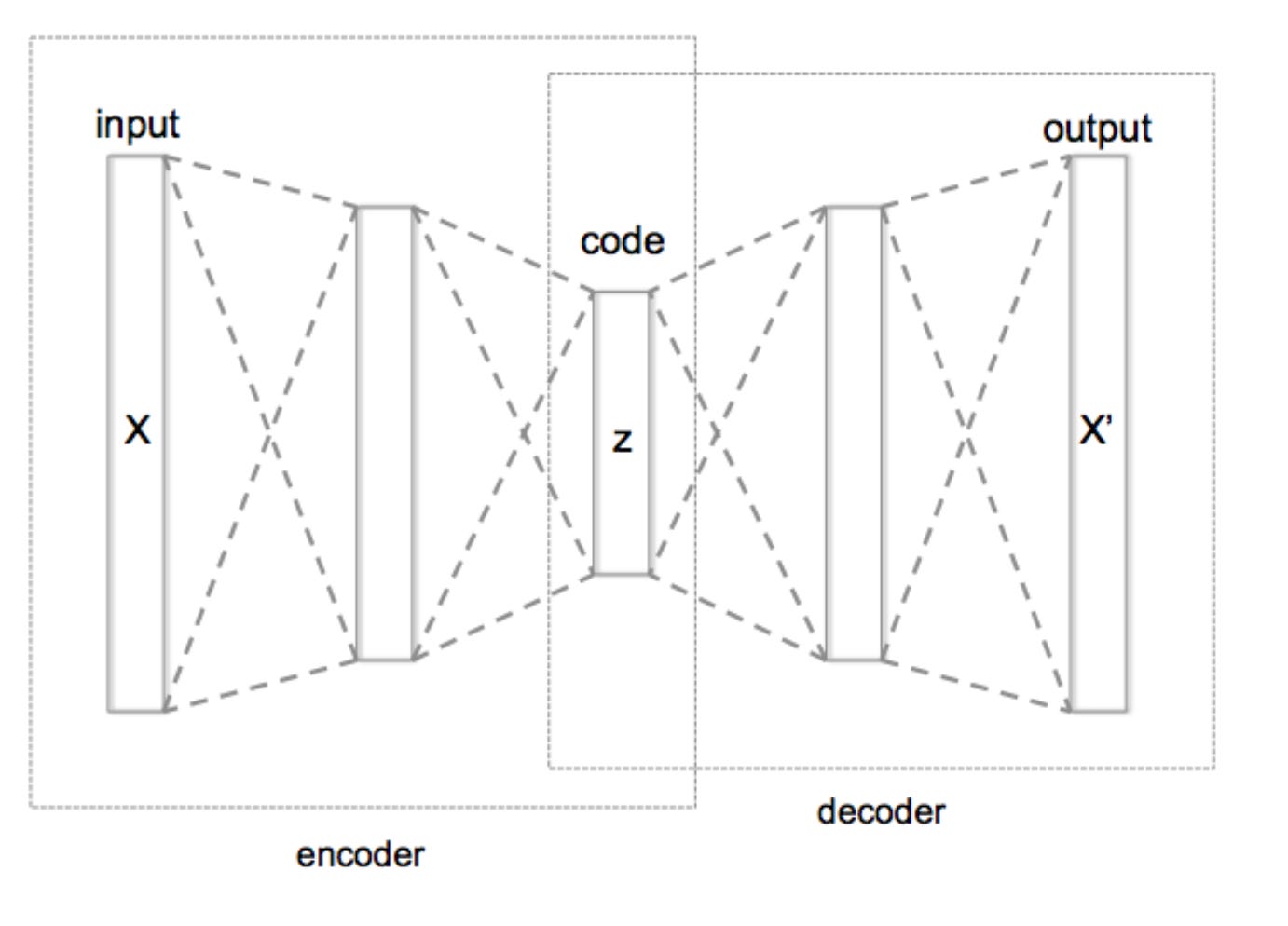
Autoencoders
An autoencoder is a neural network that attempts to map input data to output data (not necessarily in identical form). It consists of an encoder function X : R^n → R^p and decoder function X' : R^p → R^n. Both functions are represented in the neural network by successive layers of neurons.
When designing autoencoder layer sizes, the number of neurons in the middle (latent) layer is reduced to be smaller than the input layer. This forces the neural network to encode data in fewer dimensions than the original during training. This enables autoencoders to be used for data compression.
Training autoencoders aims to minimize reconstruction error while achieving maximum data compression, allowing generalization to data not present in the training set. In data compression, after processing data through the encoder, the latent layer creates an image representation with fewer parameters than pixels in the original image - this is where final data compression occurs. In the decoder, the image is reconstructed from the latent layer through successive decoder layers, typically symmetric to encoder layers.
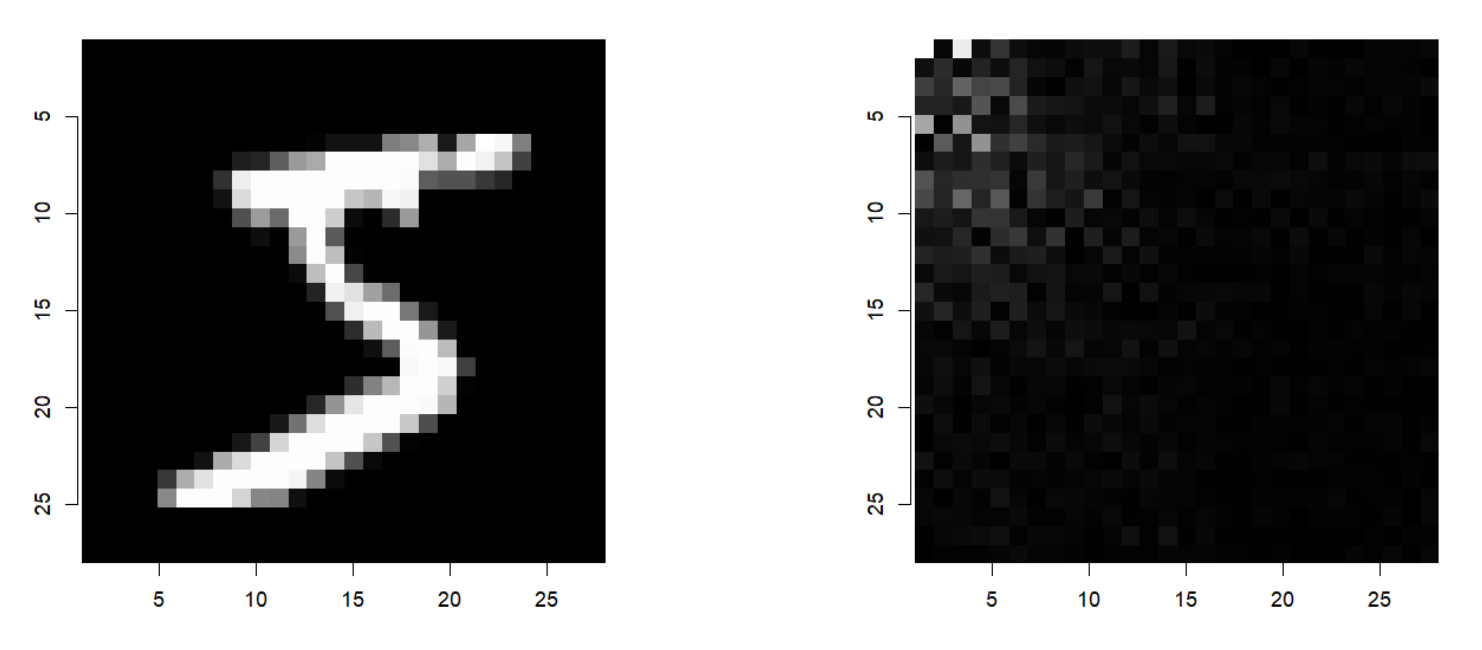
Dataset: MNIST
MNIST (Modified National Institute of Standards and Technology database) is a dataset used in machine learning for classifying images of handwritten digits from 0 to 9. This dataset is frequently used for testing machine learning algorithms due to its small number of classes and small image sizes (28×28 pixels).

Implementation
The implementation included PCA in R, DCT with various masking strategies, and convolutional autoencoders using Keras in R. All methods were evaluated at 33% compression ratio, meaning the compressed representation used one-third of the original storage space.
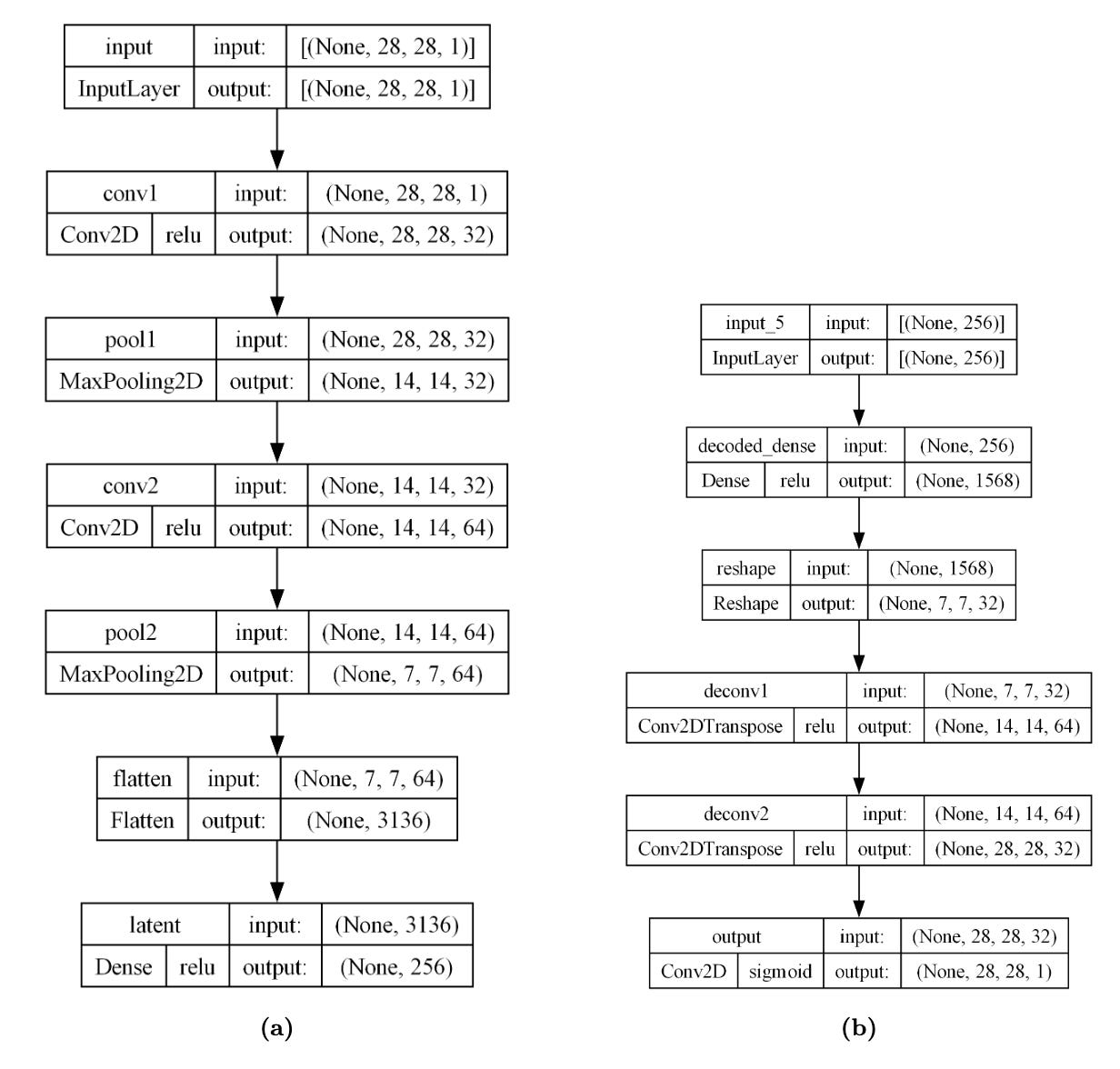
For autoencoders, both encoder and decoder were implemented with convolutional layers, then combined into a complete autoencoder model for compilation and training. The architecture used symmetric encoder-decoder structure optimized for image reconstruction.
Note: Implementation of Autoencoder in R are at the very bottom of the post.

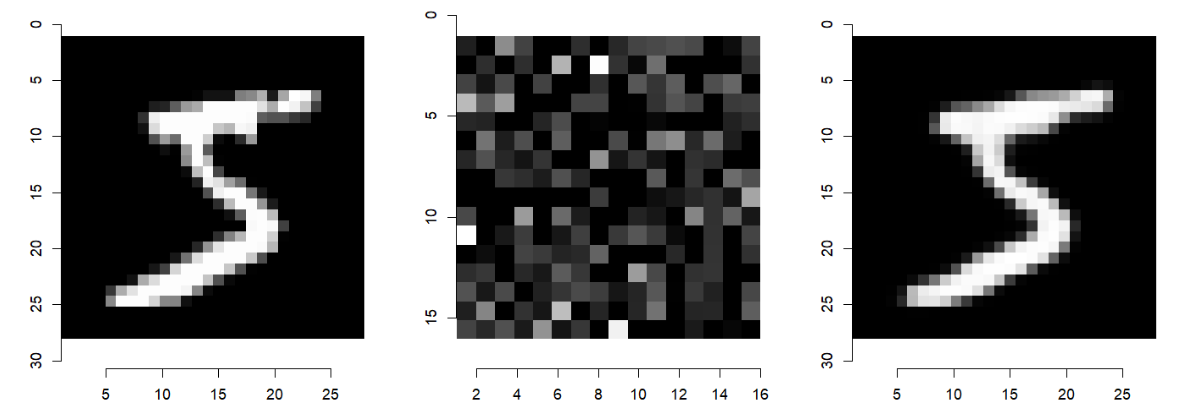
Results
Images reconstructed by autoencoders were most similar to the originals, maintaining proper shape and contrast between background and digits. The PCA method, despite satisfactory results, was characterized by grayer digit tones. DCT methods (MVC, square, and triangle variants) showed noticeable background noise and reduced contrast between digits and background.
Quantitative results confirmed visual observations:
Autoencoders: 0.97 SSIM
PCA: 0.71 SSIM
DCT variants: ~0.61 SSIM

Limitations
One disadvantage of autoencoders and PCA is the requirement for prior model training on a dataset, which limits their universality. For object types the model wasn't trained on, reconstruction quality may be significantly worse. DCT doesn't have this requirement, making it more universal.
The results obtained may be specific to the MNIST dataset, which is relatively simple and uniform in terms of shapes and colors. For more complex datasets containing multiple objects or color images, results may differ significantly.
Both PCA and autoencoders require computational resources for training, while DCT can be applied directly without preprocessing.
Possible Optimizations
For autoencoders, reconstruction quality could be improved by increasing training epochs, changing model architecture, or applying more advanced regularization techniques. Further optimization attempts might achieve similar quality results with models having even fewer parameters.
For linear methods, increasing the number of retained principal components or DCT coefficients could improve image reconstruction quality at the cost of compression ratio. For DCT, selecting more coefficients would minimize noise effects and could make results more competitive with other methods.
The trade-off between compression ratio and reconstruction quality remains fundamental across all methods, with the optimal balance depending on specific application requirements.
Autoencoder Implementation


